The study conducts an assessment of the spatial distribution of cardiovascular diseases (CVD) in Kenya by integrating spatial modeling techniques and spatial autocorrelation measures. CVDs, which refer to disorders of the heart and blood vessels, have surpassed communicable diseases as the leading cause of morbidity and mortality worldwide, posing a critical public health concern, especially in low- and middle-income countries (LMICs) where resources remain limited. A growing body of global evidence has revealed marked geographical disparities in CVD incidence, prompting investigations into small-area spatial distribution patterns. This study employed both global and local spatial autocorrelation measures to analyze CVD prevalence across Kenyan counties. The Global Moran’s I statistic was used to assess the overall degree of spatial clustering, while the Local Moran’s I identified significant clusters of high and low prevalence, alongside spatial outliers. Additionally, the Getis-Ord Gi* statistic was applied to detect statistically significant hotspots and coldspots, revealing important spatial patterns in disease prevalence. Spatial regression models were compared using the Lagrange Multiplier (LM) test, Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC) for model selection. The Spatial Lag Model (SLM) demonstrated superior performance over the Spatial Error Model (SEM) and the Spatial Durbin Model (SDM), achieving a Rao’s score (RSlag) of 16.449 and an adjusted score (adjRSlag) of 12.181, both statistically significant at the 5% level. The SLM also recorded the lowest AIC and BIC values at -380.09 and -361.80, respectively, confirming its suitability in capturing spatial dependence in the data. The findings revealed significant spatial clustering of CVD prevalence, with distinct high-risk and low-risk regions across the country. High body mass index (HBMI), tobacco use, and poor dietary habits emerged as major risk factors driving CVD prevalence, while urbanization and economic development were associated with lower disease burdens. The study highlights the importance of incorporating spatial analysis in public health planning to inform targeted interventions, optimize resource allocation, and enhance community health education campaigns aimed at promoting heart-healthy lifestyles.
| Published in | American Journal of Theoretical and Applied Statistics (Volume 15, Issue 2) |
| DOI | 10.11648/j.ajtas.20261502.14 |
| Page(s) | 59-71 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2026. Published by Science Publishing Group |
Cardiovascular Diseases (CVDS), Global Moran’s I, Local Moran’s I, Spatial Lag Model (SLM), Spatial Error Model (SEM), Spatial Durbin Model (SDM), Gertis Ord Gi* Statistic
Disease | Moran’s I | z-value | P-value |
|---|---|---|---|
Cardiovascular | 0.2048 | 2.4491 | 0.0071 |
Disease | Moran’s I Statistic | p-value |
|---|---|---|
Cardiovascular | 0.5875 | < 0.001 |
Stroke | 0.5135 | < 0.001 |
Ischemic | 0.5598 | < 0.001 |
Rheumatic | 0.4057 | < 0.001 |
Hypertensive | 0.4985 | < 0.001 |
County | Local Moran’s I | P-value | Gi* Score | Hot/Cold |
|---|---|---|---|---|
Nyeri | 2.8134 | 0.000074 | 3.9646 | Hot Spot |
Murang’a | 2.6778 | 0.000251 | 3.6613 | Hot Spot |
Kirinyaga | 2.6766 | 0.000109 | 3.8686 | Hot Spot |
Embu | 2.0347 | 0.000063 | 4.0011 | Hot Spot |
Nyandarua | 1.1412 | 0.011 | 2.5389 | Hot Spot |
Meru | 1.0305 | 0.00503 | 2.8052 | Hot Spot |
Tharaka | 0.8205 | 0.00056 | 3.4502 | Hot Spot |
Machakos | 0.7998 | 0.0121 | 2.5085 | Hot Spot |
County | Local Moran’s I | P-value | Gi* Score | Hot/Cold |
|---|---|---|---|---|
Wajir | 2.3004 | 0.0045 | -2.8384 | Cold Spot |
Garissa | 1.7446 | 0.0207 | -2.3127 | Cold Spot |
Marsabit | 1.2691 | 0.0095 | -2.5921 | Cold Spot |
Test | Statistic | Degrees of Freedom (df) | p-value |
|---|---|---|---|
RSerr | 4.3962 | 1 | 0.036 |
RSlag | 16.449 | 1 | <0.001 |
adjRSerr | 0.1291 | 1 | 0.719 |
adjRSlag | 12.181 | 1 | <0.001 |
Model | AIC value | BIC value |
|---|---|---|
Spatial Lag Model | -380.09 | -361.80 |
Spatial Error Model | -373.71 | -355.43 |
Spatial Durbin Model | -372.31 | -341.22 |
Variable | Direct Impact | Indirect Impact | Total Impact |
|---|---|---|---|
HBMI | 0.2738 | 0.2439 | 0.5177 |
Alcohol Use | -0.4054 | -0.3612 | -0.7665 |
Tobacco use | 0.2623 | 0.2337 | 0.4961 |
Dietary risks | 0.2940 | 0.2620 | 0.5560 |
GCP | -0.0004 | -0.0003 | -0.0007 |
Population Density | 0.0121 | 0.0107 | 0.0228 |
Urbanization Rate | -0.0078 | -0.0070 | -0.0148 |
Statistic | Value |
|---|---|
Sample estimate: Moran I statistic | 0.0482 |
Moran I statistic standard deviate | 0.7482 |
p-value | 0.2272 |
Expectation | -0.02222 |
Variance | 0.0087 |
CVD | Cardiovascular Disease |
GBD | Global Burden of Disease |
GCP | Gross County Product |
HBMI | High Body Mass Index |
HBP | High Blood Pressure |
KNBS | Kenya National Bureau of Statistics |
LM | Lagrange Multiplier |
NCD | Non-Communicable Diseases |
SAR | Spatial Autoregressive |
SDM | Spatial Durbin Model |
SEM | Spatial Error Model |
SR | Standardized Rate |
WHO | World Health Organization |
| [1] |
World Health Organization, ”Cardiovascular diseases”. (2021). Available from:
https://www.who.int/newsroom/fact-sheets/detail/cardiovascular-diseases-(cvds) |
| [2] | Mensah, G. A., Roth, G. A., & Fuster, V. (2019). The global burden of cardiovascular diseases and risk factors: 2020 and beyond. Journal of the American College of Cardiology, 74(20), 2529-2532. |
| [3] |
Ministry of Health, “Kenya STEPwise Survey for Non-Communicable Diseases Risk Factors 2015 Report”. Available from:
https://www.health.go.ke/wpcontent/uploads/2016/04/Steps-Report-NCD-2015.pdf |
| [4] | Mbau, L., Fourie, J. M., Scholtz, W., Nel, G., Scarlatescu, O., & Gathecha, G. (2021). PASCAR and WHF Cardiovascular diseases Scorecard project. Cardiovascular Journal of Africa, 32(3), 161-167. |
| [5] | Moraga, P. (2023). Spatial statistics for data science: theory and practice with R. CRC Press. |
| [6] | Zhang, C. (2012). Spatial weights matrix and its application. Journal of Regional Development Studies, 15, 85-97. |
| [7] | Zhou, X., & Lin, H. (2008). Spatial weights matrix. In S. Shekhar & H. Xiong (Eds.), Encyclopedia of GIS (pp. 1113-1113). Springer US. |
| [8] | Shekhar, S., Xiong, H., & Zhou, X. (Eds.). (2017). Encyclopedia of GIS (2nd ed.). Springer International Publishing. |
| [9] | Environmental Systems Research Institute. (2021). ArcGIS Pro (Version 2.8) [Computer software]. |
| [10] | Elhorst, J. P. (2014). Spatial econometrics: from crosssectional data to spatial panels (Vol. 479, p. 480). Heidelberg: Springer. |
| [11] | Yamagata, Y., & Seya, H. (Eds.). (2019). Spatial analysis using big data: Methods and urban applications. Academic Press. |
| [12] | Ruttenauer, T. (2022). Spatial regression models: a systematic comparison of different model specifications using Monte Carlo experiments. Sociological Methods & Research, 51(2), 728-759. |
| [13] | Florax, R. J., Folmer, H., & Rey, S. J. (2003). Specification searches in spatial econometrics: the relevance of Hendry’s methodology. Regional science and urban economics, 33(5), 557-579. |
| [14] | Grekousis, G. (2020). Spatial analysis methods and practice: describe-explore-explain through GIS. Cambridge University Press. |
| [15] | Addie, O., & John Taiwo, O. (2024). Predictors of diagnosed cardiovascular diseases and their spatial heterogeneity in Lagos State, Nigeria. Open Health, 5(1), 20230018. |
| [16] | Dwane, N., Wabiri, N., & Manda, S. (2020). Small-area variation of cardiovascular diseases and select risk factors and their association to household and area poverty in South Africa: Capturing emerging trends in South Africa to better target local level interventions. PLoS One, 15(4), e0230564. |
| [17] | Darikwa, T. B., & Manda, S. O. (2020). Spatial co-clustering of cardiovascular diseases and select risk factors among adults in South Africa. International Journal of Environmental Research and Public Health, 17(10), 3583. |
| [18] | Baptista, E. A., & Queiroz, B. L. (2022). Spatial analysis of cardiovascular mortality and associated factors around the world. BMC public health, 22(1), 1556. |
| [19] | Yoon, S. J., Jung, J. G., Lee, S., Kim, J. S., Ahn, S. k., Shin, E. S., Jang, J. E., & Lim, S. H. (2020). The protective effect of alcohol consumption on the incidence of cardiovascular diseases: Is it real? A systematic review and meta-analysis of studies conducted in community settings. BMC Public Health, 20, 1-9. |
| [20] | Roth, G. A., Johnson, C. O., Abate, K. H., AbdAllah, F., Ahmed, M., Alam, T., & Murray, C. J. L. (2017). Trends and patterns of geographic variation in cardiovascular mortality among US counties, 1980-2014. JAMA, 317(19), 1976-1992. |
| [21] | Zangeneh, A., Amini, S., Khalili, D., Fattahi, N., Shafiee, A., & Fotouhi, A. (2024). Epidemiological patterns and spatiotemporal analysis of cardiovascular disease mortality in Iran: Development of public health strategies and policies. Current Problems in Cardiology, 49(8), Article 102675. |
| [22] | Wang, Y., Chen, X., & Xue, F. (2024). A review of Bayesian spatiotemporal models in spatial epidemiology. ISPRS International Journal of Geo-Information, 13(3), Article 97. |
| [23] | Fabiyi, O. O., & Garuba, O. E. (2015). Geo-spatial analysis of cardiovascular disease and biomedical risk factors in Ibadan, South-Western Nigeria. Journal of Settlements and Spatial Planning, 6(1), 61-69. |
| [24] | Kandala, N.-B., Gebremedhin, G., Tlou, B., Koyanagi, A., Manda, S., & Lakew, Y. (2021). Mapping the burden of hypertension in South Africa: A comparative analysis of the national 2012 SANHANES and the 2016 Demographic and Health Survey. International Journal of Environmental Research and Public Health, 18(10), 5445. |
| [25] | Mwenzwa, E. M., & Misati, J. A. (2014). Kenya’s social development proposals and challenges: Review of Kenya Vision 2030 first medium-term plan, 2008-2012. |
| [26] | Asiki, G., Kyobutungi, C., Ezeh, A., Joshi, M. D., Oti, S., & Awuor, C. (2018). Policy environment for prevention, control and management of cardiovascular diseases in primary health care in Kenya. BMC Health Services Research, 18(1), 1-9. |
| [27] | Global Burden of Disease Collaborative Network (2022). Global Burden of Disease Study 2021 (GBD 2021) results. Seattle, United States: Institute for Health Metrics and Evaluation (IHME). |
| [28] | Kenya National Bureau of Statistics. (2023). 2019 Kenya Population and Housing Census: Volume IV- Distribution of population by socio-economic characteristics. |
APA Style
Mwangi, G. W., Wanjoya, A. K. (2026). Spatial Modeling of Cardiovascular Disease in Kenya. American Journal of Theoretical and Applied Statistics, 15(2), 59-71. https://doi.org/10.11648/j.ajtas.20261502.14
ACS Style
Mwangi, G. W.; Wanjoya, A. K. Spatial Modeling of Cardiovascular Disease in Kenya. Am. J. Theor. Appl. Stat. 2026, 15(2), 59-71. doi: 10.11648/j.ajtas.20261502.14
@article{10.11648/j.ajtas.20261502.14,
author = {Grace Wanjiku Mwangi and Anthony Kibira Wanjoya},
title = {Spatial Modeling of Cardiovascular Disease in Kenya},
journal = {American Journal of Theoretical and Applied Statistics},
volume = {15},
number = {2},
pages = {59-71},
doi = {10.11648/j.ajtas.20261502.14},
url = {https://doi.org/10.11648/j.ajtas.20261502.14},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajtas.20261502.14},
abstract = {The study conducts an assessment of the spatial distribution of cardiovascular diseases (CVD) in Kenya by integrating spatial modeling techniques and spatial autocorrelation measures. CVDs, which refer to disorders of the heart and blood vessels, have surpassed communicable diseases as the leading cause of morbidity and mortality worldwide, posing a critical public health concern, especially in low- and middle-income countries (LMICs) where resources remain limited. A growing body of global evidence has revealed marked geographical disparities in CVD incidence, prompting investigations into small-area spatial distribution patterns. This study employed both global and local spatial autocorrelation measures to analyze CVD prevalence across Kenyan counties. The Global Moran’s I statistic was used to assess the overall degree of spatial clustering, while the Local Moran’s I identified significant clusters of high and low prevalence, alongside spatial outliers. Additionally, the Getis-Ord Gi* statistic was applied to detect statistically significant hotspots and coldspots, revealing important spatial patterns in disease prevalence. Spatial regression models were compared using the Lagrange Multiplier (LM) test, Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC) for model selection. The Spatial Lag Model (SLM) demonstrated superior performance over the Spatial Error Model (SEM) and the Spatial Durbin Model (SDM), achieving a Rao’s score (RSlag) of 16.449 and an adjusted score (adjRSlag) of 12.181, both statistically significant at the 5% level. The SLM also recorded the lowest AIC and BIC values at -380.09 and -361.80, respectively, confirming its suitability in capturing spatial dependence in the data. The findings revealed significant spatial clustering of CVD prevalence, with distinct high-risk and low-risk regions across the country. High body mass index (HBMI), tobacco use, and poor dietary habits emerged as major risk factors driving CVD prevalence, while urbanization and economic development were associated with lower disease burdens. The study highlights the importance of incorporating spatial analysis in public health planning to inform targeted interventions, optimize resource allocation, and enhance community health education campaigns aimed at promoting heart-healthy lifestyles.},
year = {2026}
}
TY - JOUR T1 - Spatial Modeling of Cardiovascular Disease in Kenya AU - Grace Wanjiku Mwangi AU - Anthony Kibira Wanjoya Y1 - 2026/04/16 PY - 2026 N1 - https://doi.org/10.11648/j.ajtas.20261502.14 DO - 10.11648/j.ajtas.20261502.14 T2 - American Journal of Theoretical and Applied Statistics JF - American Journal of Theoretical and Applied Statistics JO - American Journal of Theoretical and Applied Statistics SP - 59 EP - 71 PB - Science Publishing Group SN - 2326-9006 UR - https://doi.org/10.11648/j.ajtas.20261502.14 AB - The study conducts an assessment of the spatial distribution of cardiovascular diseases (CVD) in Kenya by integrating spatial modeling techniques and spatial autocorrelation measures. CVDs, which refer to disorders of the heart and blood vessels, have surpassed communicable diseases as the leading cause of morbidity and mortality worldwide, posing a critical public health concern, especially in low- and middle-income countries (LMICs) where resources remain limited. A growing body of global evidence has revealed marked geographical disparities in CVD incidence, prompting investigations into small-area spatial distribution patterns. This study employed both global and local spatial autocorrelation measures to analyze CVD prevalence across Kenyan counties. The Global Moran’s I statistic was used to assess the overall degree of spatial clustering, while the Local Moran’s I identified significant clusters of high and low prevalence, alongside spatial outliers. Additionally, the Getis-Ord Gi* statistic was applied to detect statistically significant hotspots and coldspots, revealing important spatial patterns in disease prevalence. Spatial regression models were compared using the Lagrange Multiplier (LM) test, Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC) for model selection. The Spatial Lag Model (SLM) demonstrated superior performance over the Spatial Error Model (SEM) and the Spatial Durbin Model (SDM), achieving a Rao’s score (RSlag) of 16.449 and an adjusted score (adjRSlag) of 12.181, both statistically significant at the 5% level. The SLM also recorded the lowest AIC and BIC values at -380.09 and -361.80, respectively, confirming its suitability in capturing spatial dependence in the data. The findings revealed significant spatial clustering of CVD prevalence, with distinct high-risk and low-risk regions across the country. High body mass index (HBMI), tobacco use, and poor dietary habits emerged as major risk factors driving CVD prevalence, while urbanization and economic development were associated with lower disease burdens. The study highlights the importance of incorporating spatial analysis in public health planning to inform targeted interventions, optimize resource allocation, and enhance community health education campaigns aimed at promoting heart-healthy lifestyles. VL - 15 IS - 2 ER -
Department of Statistics and Actuarial Science, Jomo Kenyatta University of Agriculture and Technology (JKUAT), Nairobi, Kenya
Department of Statistics and Actuarial Science, Jomo Kenyatta University of Agriculture and Technology (JKUAT), Nairobi, Kenya
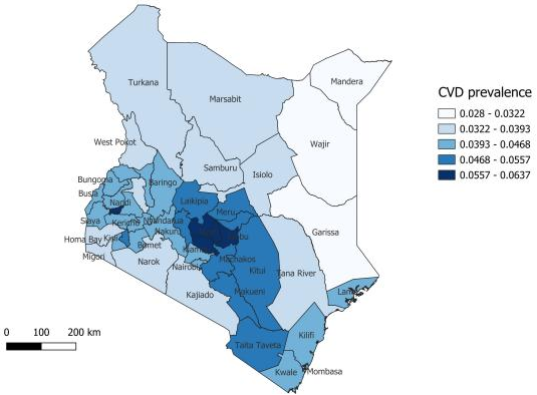
Figure 1. Spatial distribution of Cardiovascular Disease in Kenya.
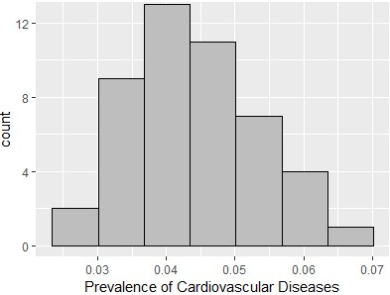
Figure 2. Cardiovascular diseases in Kenya.
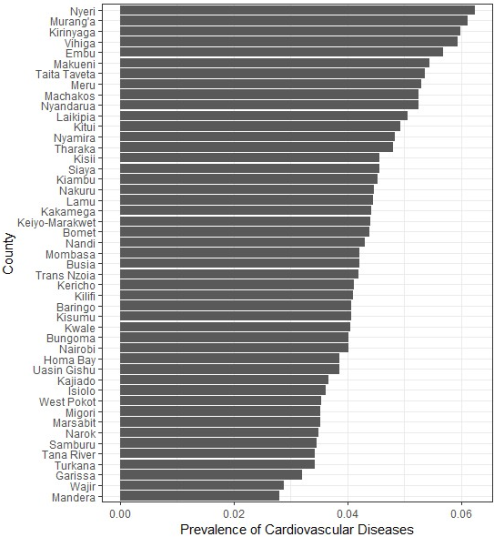
Figure 3. CVD prevalence in the counties across Kenya.
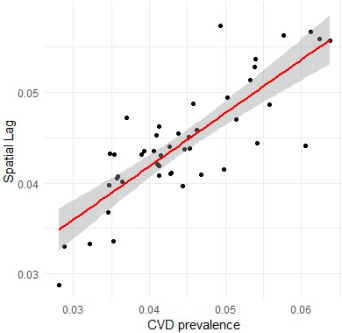
Figure 4. Spatial Lag Scatterplot.
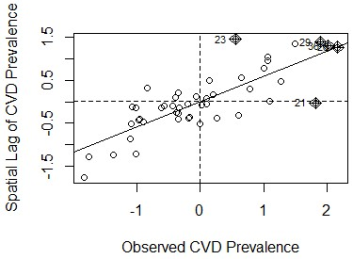
Figure 5. Moran Scatterplot.
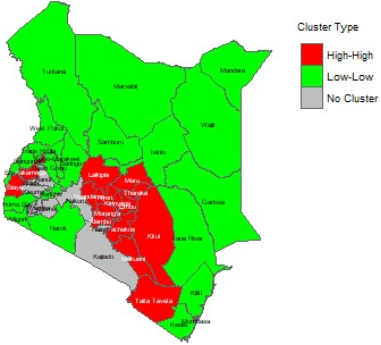
Figure 6. Hotspots and coldspots of CVD in Kenya.
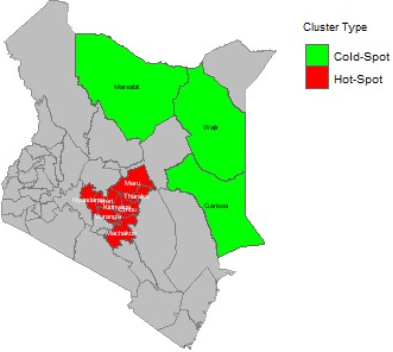
Figure 7. Significant hotspots and coldspots of CVD in Kenya.
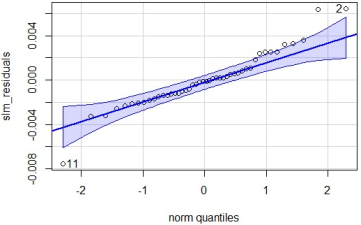
Figure 8. QQ plot of SLM residuals.
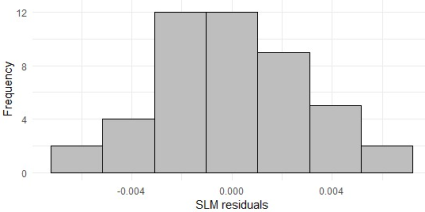
Figure 9. Histogram of residuals of SLM.
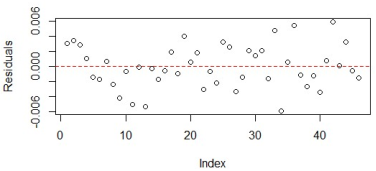
Figure 10. Residual of SLM scatter plot.

